 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Separable Fourier Neural Networks for Solving High-Frequency PDEs
May 29, 2026We propose a novel neural network architecture, termed Multi-Scale Separable Fourier Neural Networks (MS-SFNN), for the accurate and efficient solution of linear and nonlinear high-frequency partial differential equations (PDEs). MS-SFNN exploits a separable representation: given a $d$-dimensional input, it employs $d$ independent subnetworks -- each acting on a single coordinate -- and constructs basis functions via element-wise multiplication of their outputs. The PDE solution is approximated as a linear combination of these basis functions, with coefficients determined by least squares. Critically, all network weights and biases are randomly initialized once, from a uniform distribution with unit variance, and remain fixed thereafter. To enhance expressivity, a tunable scaling factor is introduced in each subnetwork to modulate the frequency content of the resulting basis functions. Fourier features are explicitly embedded through cosine activations, endowing the method with strong spectral approximation capabilities. To mitigate the memory bottleneck associated with dense collocation in high-frequency or three-dimensional problems, we replace automatic differentiation with analytically derived basis function derivatives and develop a memory-efficient batched QR decomposition algorithm for solving large-scale least-squares systems. Numerical experiments demonstrate that MS-SFNN achieves unprecedented accuracy across a range of challenging PDEs, significantly outperforming state-of-the-art methods such as Physics-Informed Neural Networks (PINN) and Separated-Variable Spectral Neural Networks (SV-SNN).
A Novel Tensor Product-Based Neural Network for Solving Partial Differential Equations
May 28, 2026This paper presents the Tensor Product Network (TPNet), a novel neural architecture for efficient and accurate function approximation and PDE solving. The core of the proposal involves constructing the solution explicitly as a linear combination of basis functions integrated into the network, with coefficients determined by a direct least-squares solve, thereby bypassing traditional gradient-based training. The key methodological contribution include: (1) an efficient tensor-product scheme that generates multi-dimensional basis functions from combinations of two sets of subnetwork outputs, significantly reducing model complexity and parameter count while maintaining expressivity; (2) a block time-marching strategy to improve computational efficiency in long-time simulations; and (3) a linear reformulation strategy for handling nonlinear PDEs by treating known nonlinear terms as sources. TPNet achieves superior accuracy and shorter training times than conventional neural network solvers. This performance gain stems from its structured design and deterministic least-squares fitting, which contrast with the iterative, often computationally intensive optimization required by mainstream methods like Physics-Informed Neural Networks (PINNs).
CyIN: Cyclic Informative Latent Space for Bridging Complete and Incomplete Multimodal Learning
Feb 04, 2026Multimodal machine learning, mimicking the human brain's ability to integrate various modalities has seen rapid growth. Most previous multimodal models are trained on perfectly paired multimodal input to reach optimal performance. In real-world deployments, however, the presence of modality is highly variable and unpredictable, causing the pre-trained models in suffering significant performance drops and fail to remain robust with dynamic missing modalities circumstances. In this paper, we present a novel Cyclic INformative Learning framework (CyIN) to bridge the gap between complete and incomplete multimodal learning. Specifically, we firstly build an informative latent space by adopting token- and label-level Information Bottleneck (IB) cyclically among various modalities. Capturing task-related features with variational approximation, the informative bottleneck latents are purified for more efficient cross-modal interaction and multimodal fusion. Moreover, to supplement the missing information caused by incomplete multimodal input, we propose cross-modal cyclic translation by reconstruct the missing modalities with the remained ones through forward and reverse propagation process. With the help of the extracted and reconstructed informative latents, CyIN succeeds in jointly optimizing complete and incomplete multimodal learning in one unified model. Extensive experiments on 4 multimodal datasets demonstrate the superior performance of our method in both complete and diverse incomplete scenarios.
MissMAC-Bench: Building Solid Benchmark for Missing Modality Issue in Robust Multimodal Affective Computing
Jan 31, 2026As a knowledge discovery task over heterogeneous data sources, current Multimodal Affective Computing (MAC) heavily rely on the completeness of multiple modalities to accurately understand human's affective state. However, in real-world scenarios, the availability of modality data is often dynamic and uncertain, leading to substantial performance fluctuations due to the distribution shifts and semantic deficiencies of the incomplete multimodal inputs. Known as the missing modality issue, this challenge poses a critical barrier to the robustness and practical deployment of MAC models. To systematically quantify this issue, we introduce MissMAC-Bench, a comprehensive benchmark designed to establish fair and unified evaluation standards from the perspective of cross-modal synergy. Two guiding principles are proposed, including no missing prior during training, and one single model capable of handling both complete and incomplete modality scenarios, thereby ensuring better generalization. Moreover, to bridge the gap between academic research and real-world applications, our benchmark integrates evaluation protocols with both fixed and random missing patterns at the dataset and instance levels. Extensive experiments conducted on 3 widely-used language models across 4 datasets validate the effectiveness of diverse MAC approaches in tackling the missing modality issue. Our benchmark provides a solid foundation for advancing robust multimodal affective computing and promotes the development of multimedia data mining.
Architecture-Optimization Co-Design for Physics-Informed Neural Networks Via Attentive Representations and Conflict-Resolved Gradients
Jan 19, 2026Physics-Informed Neural Networks (PINNs) provide a learning-based framework for solving partial differential equations (PDEs) by embedding governing physical laws into neural network training. In practice, however, their performance is often hindered by limited representational capacity and optimization difficulties caused by competing physical constraints and conflicting gradients. In this work, we study PINN training from a unified architecture-optimization perspective. We first propose a layer-wise dynamic attention mechanism to enhance representational flexibility, resulting in the Layer-wise Dynamic Attention PINN (LDA-PINN). We then reformulate PINN training as a multi-task learning problem and introduce a conflict-resolved gradient update strategy to alleviate gradient interference, leading to the Gradient-Conflict-Resolved PINN (GC-PINN). By integrating these two components, we develop the Architecture-Conflict-Resolved PINN (ACR-PINN), which combines attentive representations with conflict-aware optimization while preserving the standard PINN loss formulation. Extensive experiments on benchmark PDEs, including the Burgers, Helmholtz, Klein-Gordon, and lid-driven cavity flow problems, demonstrate that ACR-PINN achieves faster convergence and significantly lower relative $L_2$ and $L_\infty$ errors than standard PINNs. These results highlight the effectiveness of architecture-optimization co-design for improving the robustness and accuracy of PINN-based solvers.
MMPDE-Net and Moving Sampling Physics-informed Neural Networks Based On Moving Mesh Method
Nov 14, 2023



In this work, we propose an end-to-end adaptive sampling neural network (MMPDE-Net) based on the moving mesh PDE method, which can adaptively generate new coordinates of sampling points by solving the moving mesh PDE. This model focuses on improving the efficiency of individual sampling points. Moreover, we have developed an iterative algorithm based on MMPDE-Net, which makes the sampling points more precise and controllable. Since MMPDE-Net is a framework independent of the deep learning solver, we combine it with PINN to propose MS-PINN and demonstrate its effectiveness by performing error analysis under the assumptions given in this paper. Meanwhile, we demonstrate the performance improvement of MS-PINN compared to PINN through numerical experiments on four typical examples to verify the effectiveness of our method.
On the uncertainty analysis of the data-enabled physics-informed neural network for solving neutron diffusion eigenvalue problem
Mar 17, 2023In practical engineering experiments, the data obtained through detectors are inevitably noisy. For the already proposed data-enabled physics-informed neural network (DEPINN) \citep{DEPINN}, we investigate the performance of DEPINN in calculating the neutron diffusion eigenvalue problem from several perspectives when the prior data contain different scales of noise. Further, in order to reduce the effect of noise and improve the utilization of the noisy prior data, we propose innovative interval loss functions and give some rigorous mathematical proofs. The robustness of DEPINN is examined on two typical benchmark problems through a large number of numerical results, and the effectiveness of the proposed interval loss function is demonstrated by comparison. This paper confirms the feasibility of the improved DEPINN for practical engineering applications in nuclear reactor physics.
Neural Networks Base on Power Method and Inverse Power Method for Solving Linear Eigenvalue Problems
Sep 28, 2022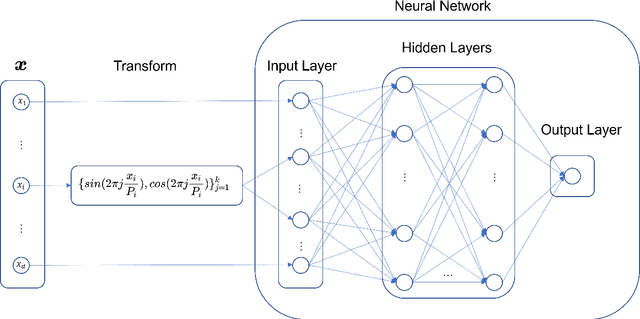
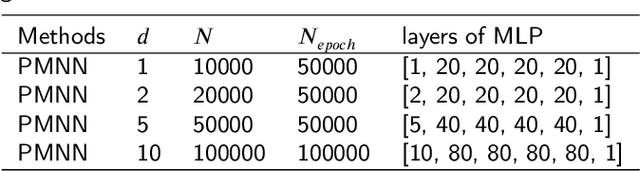
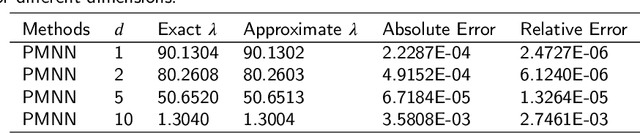
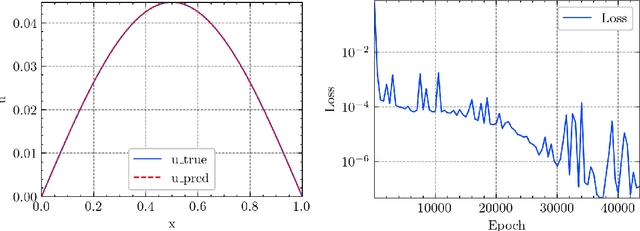
In this article, we propose three methods Power Method Neural Network (PMNN), Inverse Power Method Neural Networ (IPMNN) and Shifted Inverse Power Method Neural Network (SIPMNN) combined with power method, inverse power method and shifted inverse power method to solve eigenvalue problems with the dominant eigenvalue, the smallest eigenvalue and the smallest zero eigenvalue, respectively. The methods share similar spirits with traditional methods, but the differences are the differential operator realized by Automatic Differentiation (AD), the eigenfunction learned by the neural network and the iterations implemented by optimizing the specially defined loss function. We examine the applicability and accuracy of our methods in several numerical examples in high dimensions. Numerical results obtained by our methods for multidimensional problems show that our methods can provide accurate eigenvalue and eigenfunction approximations.